AI-Video generation technology is rapidly advancing, but most of them just produce videos without sound. Google’s video-to-audio is a next significant leap forward involves adding soundtracks to these silent videos.

Google unveiled video-to-audio (V2A) technology, enabling synchronized audiovisual generation. V2A seamlessly integrates video pixels with natural language prompts to create immersive soundscapes that complement on-screen visuals.
This technology works with video generation models like Veo, enhancing scenes with dramatic scores, realistic sound effects, and dialogue tailored to match the video’s characters and atmosphere.
It can also generate soundtracks for various types of footage, including archival material and silent films, unlocking a host of new creative possibilities.
V2A offers the capability to generate an unlimited variety of soundtracks for any video input. Users can optionally define a ‘positive prompt’ to steer the generated output towards desired sounds, or a ‘negative prompt’ to avoid undesired sounds.
This flexibility empowers users with greater control over V2A’s audio output, facilitating rapid experimentation with different audio profiles to select the most suitable match.
The diffusion-based method for audio generation yielded the most realistic and compelling results in synchronizing video and audio information.
How it works
V2A system begins by encoding video input into a compressed representation. Then the diffusion model iteratively refines audio from random noise. This iterative process is guided by both the visual input and natural language prompts provided, ensuring the creation of synchronized and realistic audio that aligns closely with the intended prompt. Finally, the audio output is decoded into an audio waveform and merged with the video data.
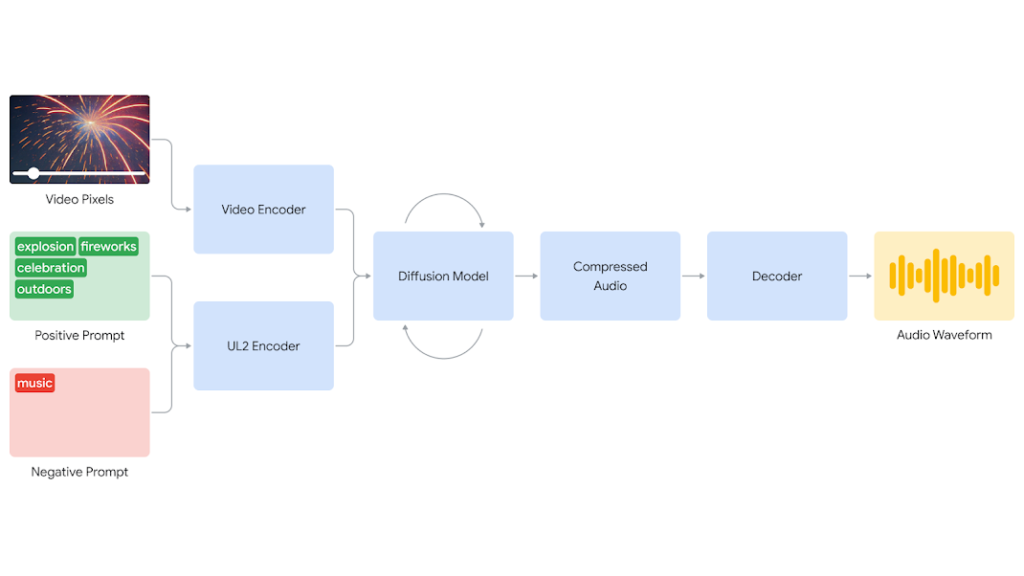
Our V2A system diagram illustrates the flow from video pixel and audio prompt input to the generation of a synchronized audio waveform. The encoding of video and audio prompts initiates the diffusion model iteration, resulting in compressed audio that is subsequently decoded into an audio waveform.
To enhance audio quality and introduce the capability to guide the model towards specific sound outputs, we enriched the training process with additional information. This included AI-generated annotations with detailed descriptions of sound characteristics and transcripts of spoken dialogue.
Through training on video, audio, and these supplementary annotations, our technology learns to associate specific audio events with visual scenes, responding dynamically to the information provided in the annotations or transcripts.
Google emphasis on its commitment to develop and deploy AI technologies with responsibility. Hopes that V2A technology will benefits the creative community positively, to improve its results Google is collecting insights and valuable feedback of its top creators and filmmakers.
Google also added SynthID in V2A research to watermark all AI-generated content to safeguard against any potential misuse of this technology.